Deep Q-Learning
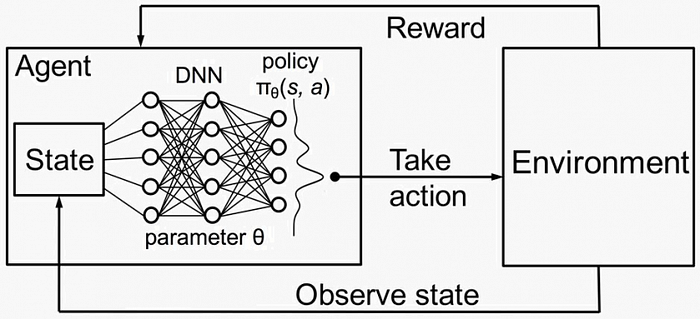
Only discrete actions,
$ \text{1. Predict }Q(s_t,a) \\ \text{2. Play action with highest Q value: }a_t=\arg\max_a Q(s_t,a) \\ \text{3. Get Reward: } R(s_t,a_t) \\ \text{4. Reach next state: } s_{t+1} \\ \text{5. Append transition to the memory } (s_t,a_t,r_t,s_{t+1}) \rightarrow M\\ \text{6. Take a random batch }B\subset M \\ \text{Get predictions and targets: }Q(s_{t_B},a_{t_B}) \text{ and }R(s_{t_B},a_{t_B})+\max_a Q(s_{t_{B+1}},a)\\ \text{7. Compute Loss} \\ $ $$\mathcal{L}=\frac{1}{2}\sum_B\big(R(s_{t_B},a_{t_B})+\max_a Q(s_{t_{B+1}},a)-Q(s_{t_B},a_{t_B})\big)^2=\frac{1}{2}\sum_B TD_{t_B}(s_{t_B},a_{t_B})^2 $$