Spark with Pi Cluster 3
Java Installation
This can be done for all nodes.
clustercmd 'sudo apt install -y default-jre > /dev/null 2>&1'
clustercmd java -version
clustercmd 'sudo apt install -y default-jdk > /dev/null 2>&1'
clustercmd df -h
clustercmd 'sudo apt install -y scala > /dev/null 2>&1'
clustercmd scala -version
echo 'export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::")' >> ~/.bashrc
The following sections are only applied to first Node (master node/ name node). Other datanodes can be done in later article.
Hadoop Installation
Download the correct tar file, by clicking Announcement under Release notes → Download tar.gz (not src!!)
scp hadoop-3.3.1.tar.gz pi41:
sudo tar -xvf hadoop-3.3.1.tar.gz -C /opt/
sudo mkdir hadoop
sudo mv hadoop-3.3.1/* hadoop
sudo rm -r hadoop-3.3.1
sudo chown pi:pi -R /opt/hadoop
echo 'export HADOOP_HOME=/opt/hadoop' >> ~/.bashrc
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> ~/.bashrc
# edit /opt/hadoop/etc/hadoop/hadoop-env.sh to add this line
export JAVA_HOME=$(readlink –f /usr/bin/java | sed "s:bin/java::")
echo 'export JAVA_HOME=$(readlink –f /usr/bin/java | sed "s:bin/java::")' >> /opt/hadoop/etc/hadoop/hadoop-env.sh
source ~/.bashrc
Test with,
cd && hadoop version | grep Hadoop
Spark Installation
Download the correct tar file under Download Apache Spark → Step 3.
scp spark-3.1.2-bin-hadoop3.2.tgz pi41:
sudo tar -xvf spark-3.1.2-bin-hadoop3.2.tgz -C /opt/
cd /opt && sudo mkdir spark
sudo mv spark-3.1.2-bin-hadoop3.2/* spark
sudo rm -r spark-3.1.2-bin-hadoop3.2
sudo chown pi:pi -R /opt/spark
echo 'export SPARK_HOME=/opt/spark' >> ~/.bashrc
echo 'export PATH=$PATH:$SPARK_HOME/bin' >> ~/.bashrc
source ~/.bashrc
Test with,
spark-shell --version
Configure HDFS
Please configure these in Pi1 as master node, all files are within /opt/hadoop/etc/hadoop,
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://pi41:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop_tmp/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Run the following commands to refer the change,
sudo mkdir -p /opt/hadoop_tmp/hdfs/datanode
sudo mkdir -p /opt/hadoop_tmp/hdfs/namenode
sudo chown pi:pi -R /opt/hadoop_tmp
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
Test with,
hdfs namenode -format -force # only do this at the first time, otherwise it will cause data lost in hdfs, to fix it see Troubleshooting section.
start-dfs.sh
start-yarn.sh
jps # must show NameNode, DataNode, NodeManager, ResourceManager, SecondaryNameNode, Jps. Otherwise, see Troubleshooting section.
Basic commands to control file system (fs), they look like extra layer to do linux bash,
hadoop fs -mkdir /tmp
hadoop fs -ls /
#### Continue to test ####
hadoop fs -put $SPARK_HOME/README.md /
spark-shell # start spark host
scala> val textFile = sc.textFile("hdfs://pi41:9000/README.md")
...
scala> textFile.first()
res0: String = # Apache Spark
In your browser, type in http://{pi41_ip}:4040 or http://{pi41_ip}:8088, you should see the spark console as follows,
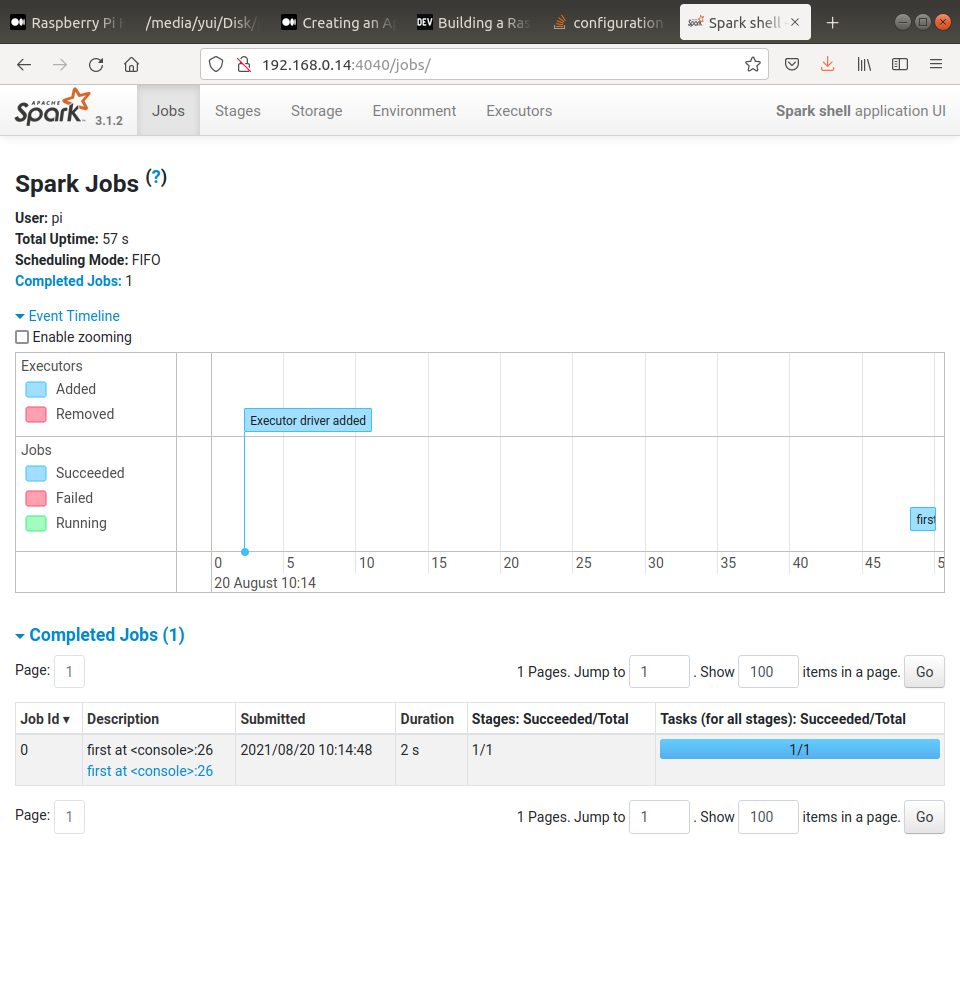
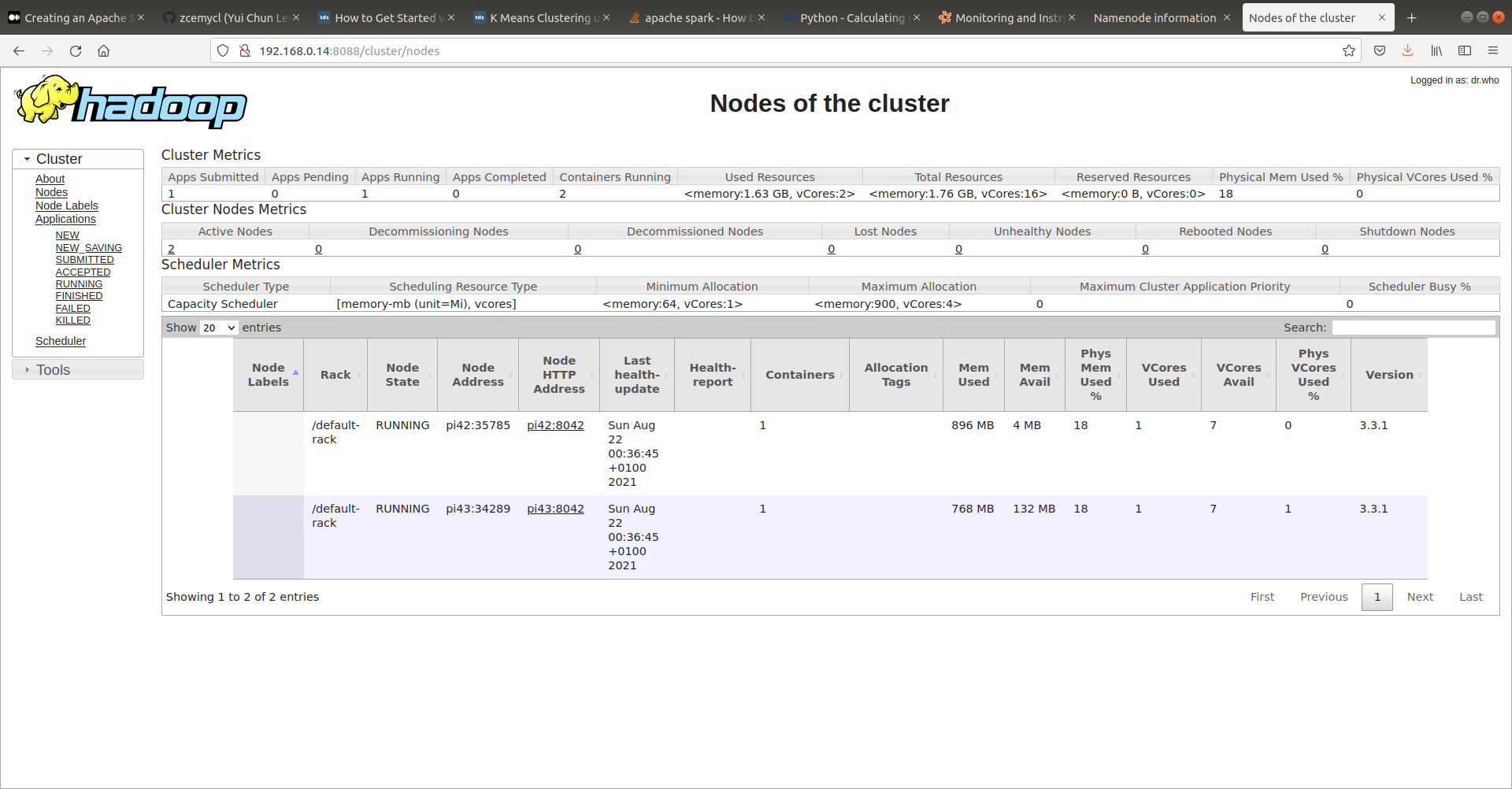
Troubleshootings
- Hide
execstackWarning, i.e.You have loaded library... which might have disabled stack guard. - Hide
NativeCodeLoaderWarning, i.e.Unable to load [the] native-hadoop library for your platform, - Restart properly,
- Missing datanode by
jpsand eroorHadoop java io IOException File could only be replicated to 0 nodes instead of minReplication 1when runninghadoop fs -put $SPARK_HOME/README.md /, caused by accidentally commandhdfs namenode -format -forceagain,
# edit /opt/hadoop/etc/hadoop/hadoop-env.sh
export HADOOP_OPTS="-XX:-PrintWarnings –Djava.net.preferIPv4Stack=true"
echo 'export HADOOP_HOME_WARN_SUPPRESS=1' >> ~/.bashrc
echo 'export HADOOP_ROOT_LOGGER="WARN,DRFA"' >> ~/.bashrc
source ~/.bashrc
# Method 1 reboot, then run start-xxx.sh commands
# Method 2
stop-all.sh && start-dfs.sh && start-yarn.sh
sudo rm -r /opt/hadoop_tmp
sudo mkdir -p /opt/hadoop_tmp/hdfs/datanode
sudo mkdir -p /opt/hadoop_tmp/hdfs/namenode
sudo chown pi:pi -R /opt/hadoop_tmp
# Now rerun everything again,
hdfs namenode -format -force
start-dfs.sh
start-yarn.sh # show work
References
- A Data Science/Big Data Laboratory — part 1 of 4: Raspberry Pi or VMs cluster — OS and communication
- A Data Science/Big Data Laboratory — part 2 of 4: Hadoop 3.2.1 and Spark 3.0.0 over Ubuntu 20.04 in a 3-node cluster
- Building a Raspberry Pi Hadoop / Spark Cluster
- Installing and Running Hadoop and Spark on Ubuntu 18
- Build Raspberry Pi Hadoop/Spark Cluster from scratch
- Spark with Python (PySpark) Tutorial For Beginners
- Download Apache Hadoop
- Download Apache Spark
- Raspberry Pi 4: How To Install Apache Spark
- Creating an Apache Spark Cluster with Raspberry Pi Workers
- Raspberry Pi Hadoop Cluster Guide