Spark with Pi Cluster 4
Now the cluster setup should begin. Previous chapter only prepares you to have a single-node cluster and that single node acts as both a master and a worker node. To set up the worker nodes, the following steps are required,
Installation of Hadoop in every pi
clustercmd sudo mkdir -p /opt/hadoop_tmp/hdfs
clustercmd sudo chown pi:pi -R /opt/hadoop_tmp
clustercmd sudo mkdir -p /opt/hadoop
clustercmd sudo chown pi:pi -R /opt/hadoop
for pi in $(otherpis); do rsync –avxP $HADOOP_HOME $pi:/opt; done
In ~/.bashrc file, add these lines
export JAVA_HOME=$(readlink –f /usr/bin/java | sed "s:bin/java::")
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
export HADOOP_HOME_WARN_SUPPRESS=1
export HADOOP_ROOT_LOGGER="WARN,DRFA"
before,
# If not running interactively, don't do anything
case $- in
*i*) ;;
*) return;;
esac
Test with,
clustercmd hadoop version | grep Hadoop
# if command not found, please follow the instruction above strictly so that export command is run when ssh is not interactive, or,
clustercmd /opt/hadoop/bin/hadoop version | grep Hadoop
clustercmd sudo -E env "PATH=$PATH" hadoop version | grep Hadoop
clustercmd 'export PATH=$PATH:/opt/hadoop/bin && hadoop version | grep Hadoop'
Installation of Spark in every pi
clustercmd sudo mkdir -p /opt/spark
clustercmd sudo chown pi:pi -R /opt/spark
for pi in $(otherpis); do rsync –avxP $SPARK_HOME $pi:/opt; done
Configuring Hadoop on the Cluster
Make these changes in the folder /opt/hadoop/etc/hadoop of all servers, including master node and workers node.
core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://pi41:9000</value>
</property>
</configuration>
hdfs-site.xml
Replication is set to 2 because I want the file is copied to 2 datanodes.
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop_tmp/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>128</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>128</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>pi41</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>900</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>900</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>64</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
master
pi41
workers
pi42
pi43
Then, clear all the tmp files in datanode and namenode, and start the hdfs again,
clustercmd rm -rf /opt/hadoop_tmp/hdfs/datanode/*
clustercmd rm -rf /opt/hadoop_tmp/hdfs/namenode/*
hdfs namenode -format -force # only in pi41
start-dfs.sh && start-yarn.sh
Test the configuration with, open http://{pi41_ip_address}:9870 in browser,
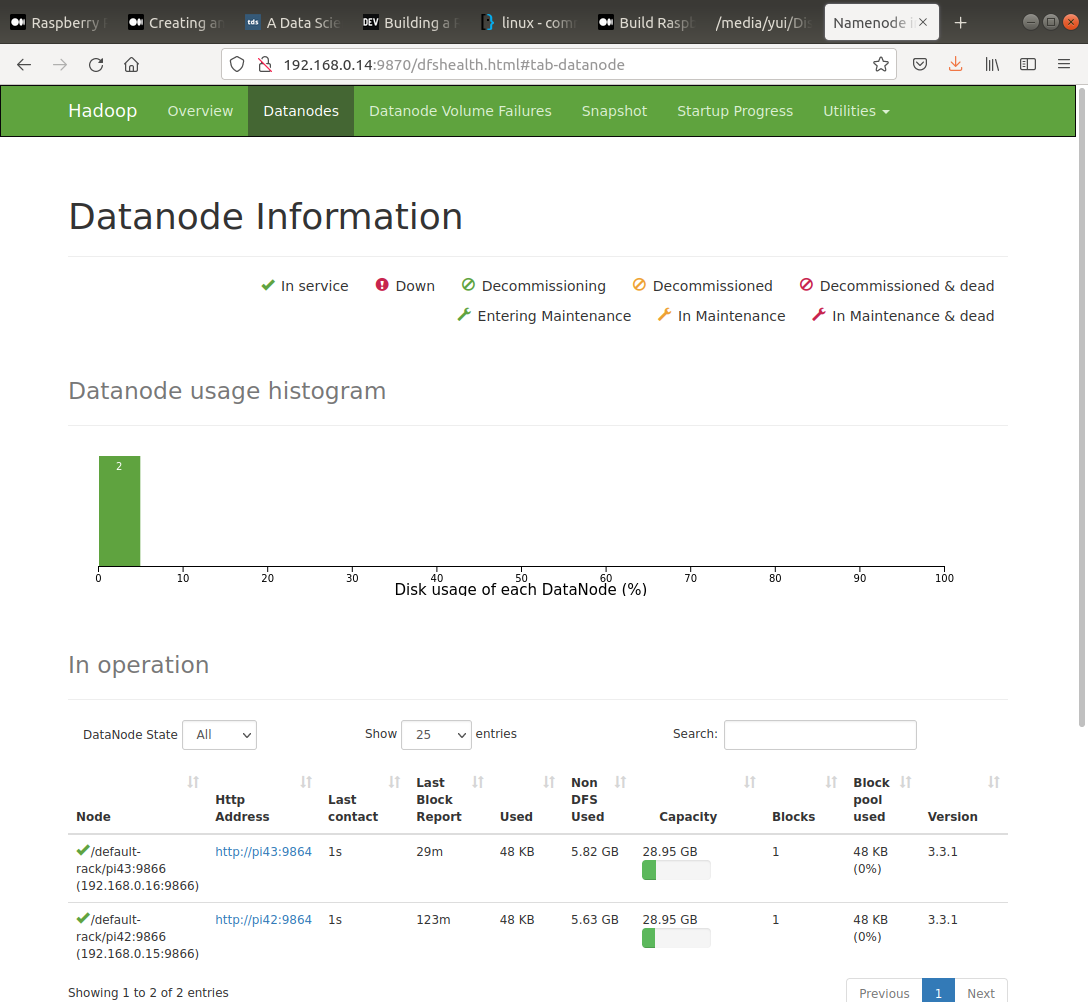
jps # In pi41, should not have datanode. In pi42 and pi43 should have datanode.
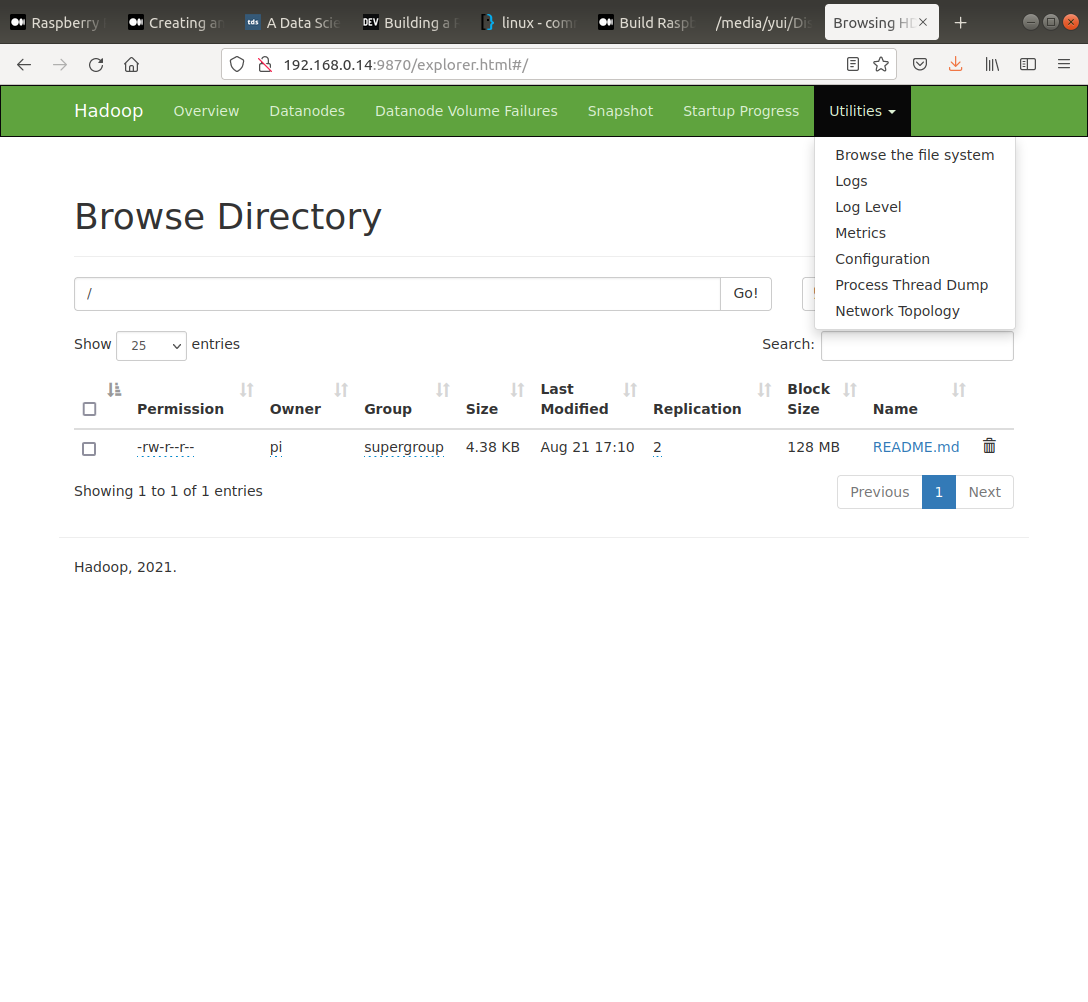
hadoop fs -put $SPARK_HOME/README.md / # this should be put into datanode 1 and 2 (pi42 and pi43).
ls /opt/hadoop_tmp/hdfs/datanode # In pi41, should be empty. In pi42 and pi43, should have a folder named current.
Configuring Spark on the Cluster
# Add these to ~/.bashrc
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:$LD_LIBRARY_PATH
# Edit spark-defaults.conf
cd $SPARK_HOME/conf
sudo mv spark-defaults.conf.template spark-defaults.conf
# Add these to spark-defaults.conf
spark.master yarn
spark.driver.memory 465m
spark.yarn.am.memory 356m
spark.executor.memory 465m
spark.executor.cores 2
# Start dfs
stop-dfs.sh && stop-yarn.sh
start-dfs.sh && start-yarn.sh
Test with,
spark-submit --deploy-mode client --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-3.1.2.jar 7
# 2 datanodes: took 35.576593 s , Pi is roughly 3.140290200414572
# 1 datanode :